

#Wide & Deep Learning for Recommender Systems阅读笔记
Wide指的是线性模型,Deep指的是DNN。这篇论文提出了一个联合训练线性模型和DNN的的算法,可以同时发挥出两个不同模型的优势:线性模型有“Memorization”的优点,DNN有”Generalization”的优点。”Memorization”是指模型的记忆能力,也即是可以记住item之间或者features之间的组合是否同时出现过;”Generalization”是指模型探索发现特征之间新的组合的能力,对比与”Memorization”,”Generalization”可以使推荐系统的推荐更加多元化。
Wide & Deep Learning
Wide&Deep的结构如下图中间所示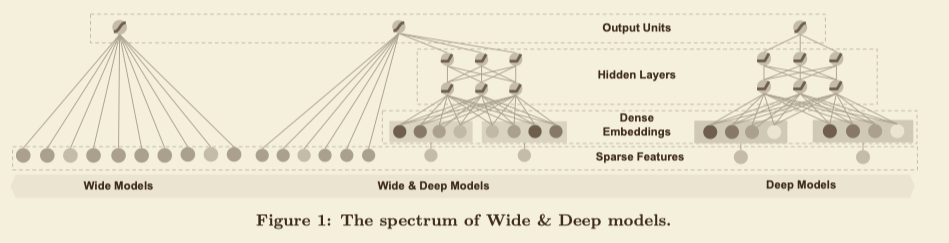
Wide component
上图的左侧就是Wide的部分,其实就是一个线性模型,这一侧的输入特征主要包括原始的特征以及经过非线性变换后的特征
Deep component
上图的右侧就是Deep的部分,这是一个DNN结构,这一侧的输入特征为经过one-hot编码后的稀疏特征,然后学习一个稠密的embedding作为DNN的输入。
联合训练Wide&Deep
将wide部分以及Deep部分的输出层组合联合训练得到:
$$
P(Y=1|x) = \sigma(w_{wide}^T[x, \phi(x)] + w_{deep}^Ta^{l}+b)
$$
论文中提到,在实际中是使用FTRL训练Wide部分,使用AdaGrad训练Deep部分。
系统应用
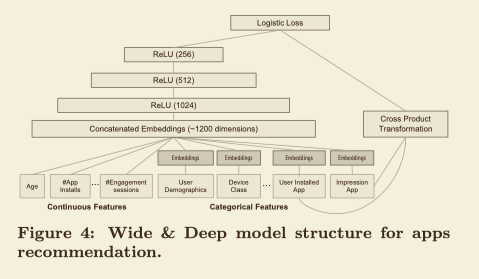
在将此模型应用于APPs推荐的框架中,Deep侧首先将categorical特征的热编码学习一个embedding,然后将embedding和continuous特征连接起来作为DNN的输入;Wide侧一些categorical特征的交叉积变换作为特征输入。
附上自己实现模型的代码wide_deep