

YouTube的推荐系统架构主要有两部分组成,首先是从百万级数据中产生一个候选集,这个候选集可能只包含数百个待推荐的视频,其次是对这个候选集中的视频进行排序,如下图所示:
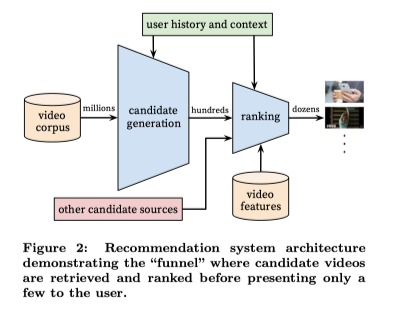
这个系统的每一部分都对应着一个推荐模型,首先看一下产生候选集的模型。
候选集生成模型
生成候选集的这一模型将推荐视为一个多分类问题,用户u在时间t观看视频i的概率可用公式计算:
$$
P(w_t=i | U, C) = \frac{e^{v_iu}}{\sum_{j \in V} e^{v_ju}}
$$
其中$u,v_i$分别是用户和视频的embedding向量,是在模型的训练过程中产生的,正如下面的架构图所示的,u应该是三层全连接网络的输出,而v是softmax层的权重。这一模型的整体架构如下图所示
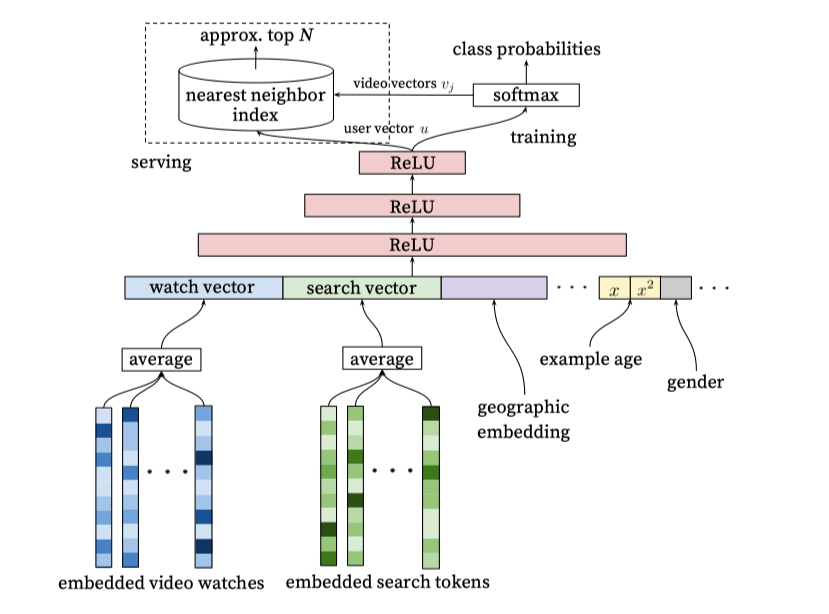
模型的输入
输入特征主要包括视频的embedding向量,用户搜索关键词的embedding,若一个用户同时有多个视频embedding和多个搜索关键词则采取的操作是简单平均法,需要注意的是,这些embedding向量都是训练学习得到的,也就是说模型实际输入的是视频和关键词的one-hot编码,然后将这些稀疏的编码映射为稠密的embedding作为网络的输入。另外输入特征还包括了用户的一些属性特征和视频的自身属性特征,将这些特征拼接起来作为深度网络的输入层。
隐藏层
隐藏层是金字塔形的全连接网络,使用Relu作为激活函数。
输出层
在训练的时候,全连接网络的最后一层输出作为用户的embedding向量u,而全连接最后一层到softmax的权重作为视频的embedding向量。在线上预测的时候,模型并没有使用softmax计算概率,而是采用了近邻搜索的方法。
如何构造样本和标签
从模型的结构上来看,这一模型实际上是借鉴了CBOW语言模型,也就是说一个用户的观看历史可以看做一个序列,这一序列中的每个时间节点观看的视频都是一个带分类的label,而这一label周围的固定长度的视频则作为它的输入特征,如下如的a图所示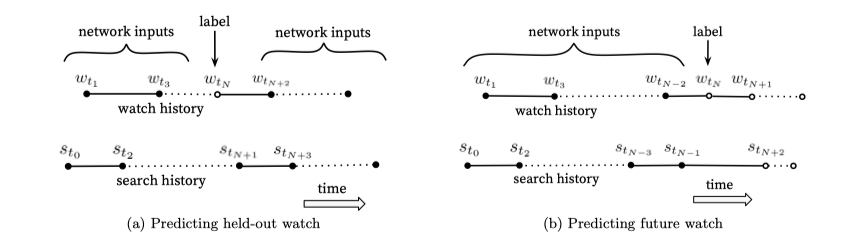
但是若采用a图的方式构造样本,容易泄露未来的信息,因为视频序列和文本信息不同,视频序列是一种非对称的序列,下一时刻的视频是还没有观看的,所以不能用未来的视频信息来预测当前视频的label,故文章中所使用的构造样本的方式是b图中方法,只用过去看过的视频作为当前label的输入。
#排序模型
生成候选集之后,候选集中的视频大概有上百个,也不能把所有的视频推荐给用户,还需要对这些视频进行进一步的打分排序,在这一阶段,同样使用了与产生候选集相识的模型结构,如图所示
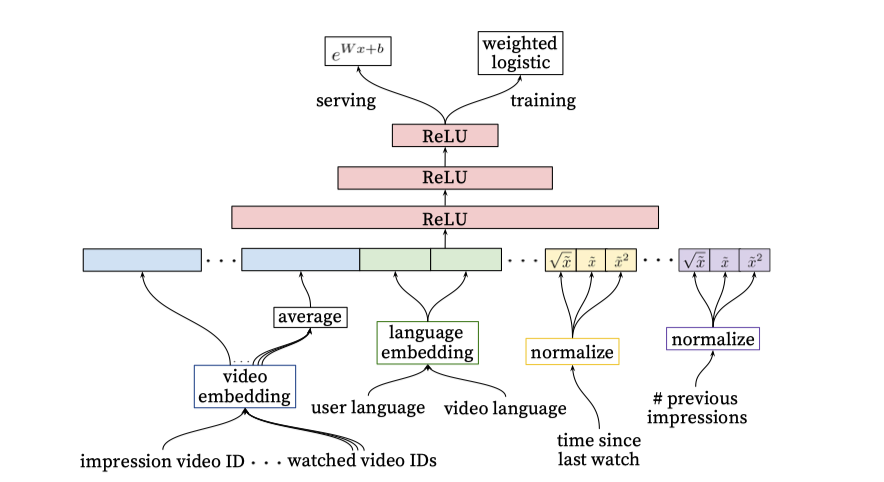
所不同的是排序模型把推荐问题看成一个二分类问题,最后一层使用的带权重的逻辑回归。
特征构造
整体上还是把特征分为continuous特征和categorical特征,categorical特征(视频ID编码和用户语言视频语言编码)的处理方式依旧是学习出embedding向量作为DNN的输入;continuous特征包括一些上下文信息和用户与视频交互的一些历史信息,在输入continuous特征之前需要标准化处理。
对观看时间建模
这部分主要介绍为什么使用带权重的逻辑回归作为损失函数。论文中给的理由是模型的主要目的是预测视频观看的时长而非只预测用户是否点击视频,因为如果只预测用户是否点击作为目标,很容易受标题党的影响。给定正样本,正样本的权重是用户观看的时长(但是没有明确时长的单位是s还是min),负样本的权重是单位1。